検索エンジンのクローラーとはなにか?その基本的な仕組みとクロールバジェット
クローラーはウェブ上を自動巡回し、検索エンジンのインデックス(データベース)に情報を集めるプログラムです。代表的なクローラーには Googlebot や Bingbot があります。
クロールのおもなステップ
- URL の発見: 外部・内部リンクやサイトマップから新規 URL を取得
- robots.txt の確認: アクセス許可の有無を事前にチェック
- HTML の取得: 許可された URL からページの HTML を取得
- リンクと構造の解析: HTML 内のリンクを分析しクロール対象を追加
- インデックス登録判定: 重複判定や noindex タグの有無などを確認
クロールバジェットとは
クロールバジェットは Google などの検索エンジンが 1 つのサイトに割り当てる巡回リソース(クロールできる回数や量)の上限を表すために、 SEO の文脈で使われる造語です。 Google が公式に定義しているわけではありませんが、ウェブサイト運営者にとっては非常に重要な概念です。
クロール以降のプロセス:Google がコンテンツを「理解」し「保存」するまで
クローラーが新しいウェブページの情報を取得した後、 Google がそのページを検索結果に表示するまでには、さらに「レンダリング」と「インデックス登録」という重要なステップがあります。
レンダリング
Google がページの内容を「理解」するプロセスです。現代のウェブページは JavaScript による動的なコンテンツ生成が多く、クローラーが HTML を取得するだけでは不十分です。 Google は WRS(Web Rendering Service)で実際のブラウザ相当の処理を行い、ページの全容を把握します。
- Web Rendering Service(WRS)への送付: 取得した HTML は Google の WRS でレンダリングされます。 WRS は最新の Google Chrome をベースにしたエンジンです。
- リソースの追加取得: レンダリングには HTML だけでなく、 CSS や JavaScript 、画像、フォントといった追加のリソースも必要です。 WRS はこれらをダウンロードし、ユーザーがブラウザで見るのと同じようにページを再現します。
- ページ構築・ JavaScript 実行: レンダリングによって JavaScript が実行され、動的に生成されたコンテンツも Google は完全に理解できるようになります。
レンダリングが不完全だと、ページ内容が正しく認識されず、 SEO 評価やインデックスに悪影響を及ぼす可能性があります。
インデックス登録
Google はページ内容を解析し、巨大な検索データベース(インデックス)に保存します。
- 情報解析・保存: インデックス登録の際、 Google はキーワード、コンテンツの種類、テーマ、構造、被リンク、ページの品質、更新頻度など、あらゆる情報を総合的に解析し、データベースに保存します。
- 評価: インデックス登録される際、 Google はページの信頼性、関連性、有用性などを評価し、将来的な検索順位を決定するための重要な材料とします。
- noindex での除外: 特定のページを検索結果に表示したくない場合は、 HTML のセクションに noindex メタタグを記述することで、インデックス登録から除外するよう Google に指示できます。
ランキング
インデックス登録されたページは最終的に Google の検索結果に表示される準備が整います。ユーザーが検索クエリを入力すると、 Google のアルゴリズムはインデックス内の数兆ものウェブページの中から、そのクエリに最も関連性の高いページを瞬時に見つけ出し、順位付け(ランキング)を行います。
ランキング要因には、コンテンツの品質、キーワードの関連性、被リンクの質と量、ページの読み込み速度、モバイル対応、ユーザーエクスペリエンスなど、 200 以上の複雑な指標が含まれており、これらの要因は常に進化し続けています。
クローラー最適化のための実務的対策
ここまで解説してきた一連のプロセスを円滑に進め、ウェブサイトの SEO パフォーマンスを最大化するために、以下の実務的な対策を実践しましょう。
| 対策 | ポイント |
|---|---|
| XML サイトマップ送信 | クロールしてほしい URL を優先的に Google に通知 |
| robots.txt の適切な設定 | 不要領域のクロールを防ぎ、重要ページに巡回リソースを集中 |
| 内部リンク最適化 | サイト内リンク構造を整理し、重要ページへクローラーを誘導 |
| canonical タグの活用 | 重複ページの評価分散を防ぎ、正規 URL を明示 |
| エラー修正 | 404 等のエラー・重複を減らし、クロール効率とサイト健全性を向上 |
つまり、内部リンクによる導線をしっかり構築することが、クローラーがサイト内を効率的に巡回し、重要なページを発見するための鍵。構造化データもページの内容を正しく理解することの助けとなります。
noindex タグは?
noindex タグは直接的なクロールバジェットの節約にはつながりません。このタグを認識するために、そのページをクロールして HTML を読み込む必要があるため、その分のクロールは発生します。 noindex の目的はあくまでインデックスからの除外です。
しかし、長期的には、不要なページへの noindex はそのサイトのインデックスを効率的に管理しやすくなる可能性はあります。結果的に重要なページのクロール頻度が最適化されるといった間接的な恩恵が考えられます。クロールそのものを避けたい場合は robots.txt での Disallow が基本的な手段となります。
Search Console でクロール状況を見える化
Google Search Console は、 Google がウェブサイトをどのようにクロールし、インデックスしているかを把握するための不可欠なツールです。
- カバレッジレポートでインデックス済・対象外ページと理由を確認
- クロール統計情報でクローラーの巡回頻度やレスポンス速度を把握
- URL 検査ツールで個別ページの HTML やレンダリング結果を可視化
- サイトマップ管理でサイトマップの送信・反映状況をモニタリング
設定→クロールの統計情報
Search Console では、「設定」→「クロールの統計情報」 から、以下の詳細なデータを確認することで、クローラーの巡回頻度の傾向を把握できます。
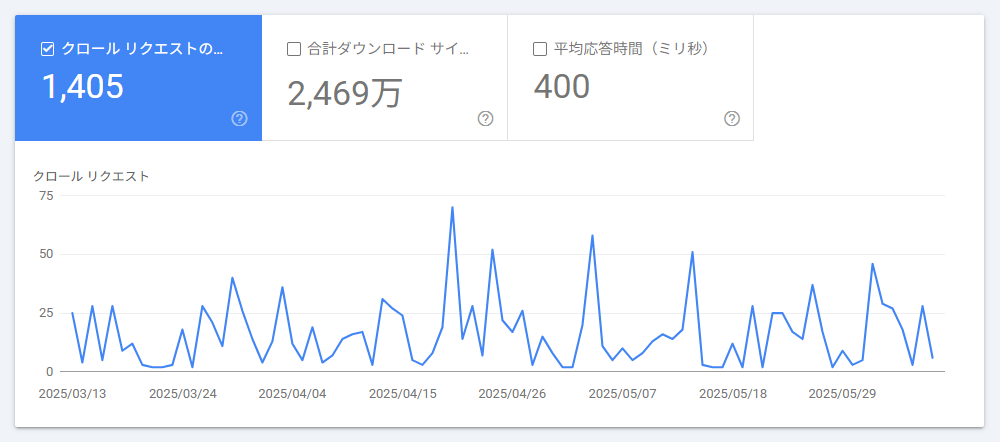
以前の Search Console には、クロール頻度を手動で調整できる機能が存在していましたが、現在は廃止されています。 Google は「高品質なコンテンツを安定提供しているサイトに対しては、自動的にクロール頻度を最適化する」としており、ユーザー関与の必要性を除外しているといえるでしょう。
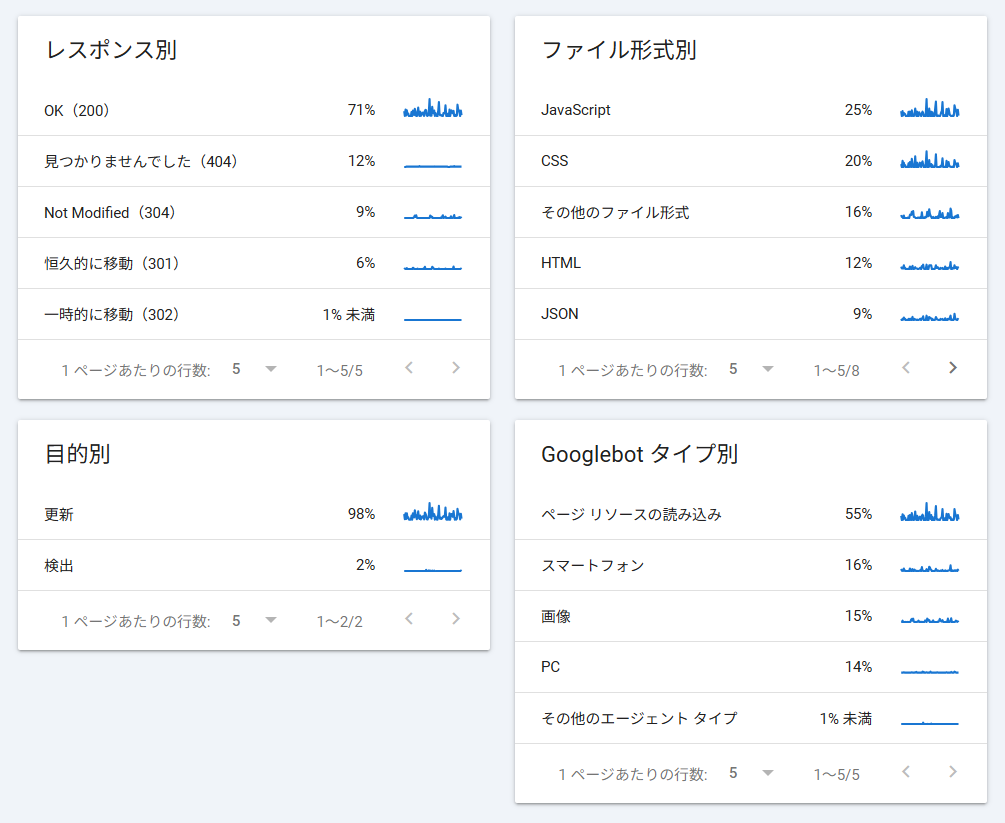
クローラ対策で注目すべき指標とは
クローラーの動きをより深く理解するためには、 Search Console の情報だけでなく、サーバーログなどのデータも活用することが有効です。
- User-Agent で「どの検索エンジンが巡回しているか」
- アクセス先 URL で「どのページがクロール対象になっているか」「クロールされていない重要ページがないか」
- ステータスコードで「クロール時のエラーやアクセス不可ページがないか」
- アクセス頻度やアクセス数で「どのくらい定期的に Googlebot が来ているか」「頻度の増減傾向」
残念ながら、 Search Console の情報には限界もあります。例えば、もっとも基本的な指標といえるどのページにクローラーが訪れているかは直接確認できません。これはサーバーログを直接確認する必要があります。
サーバーログの例
66.249.66.1 - - [13:00:00] "GET /index.html"
66.249.66.1 - - [14:01:20] "GET /about.html"
66.249.66.1 - - [14:53:10] "GET /products/item-01.html"
※この IP アドレスのホスト名は crawl-66-249-66-1.googlebot.com となっており、これは Googlebot (Google の検索エンジンのクローラー) が利用する IP アドレスであることが示唆されます。
では、クローラーは一度のセッションでサイト内の複数ページを巡回していくか答えられる方はいらっしゃいますか?
答えはノーです。
基本的に単一ページごとしか見ていないと考えられます。
なぜ、そう答えられるかと言えば、実際のクローラーがどのように動いているか解析しているからです。
クローラー解析の探求
Search Console やサーバーログによる解析には限界もあります。わたしはより詳細なクローラー挙動の分析のために、自開発の仕組みによりクローラーを解析しています。(GA4 にクローラーのデータを送信する WordPress のプラグインの形)
もし、ご自身のサイトでクローラー挙動をもっと深く知りたい方はぜひお問い合わせください。プロット数がまだまだ少ないので、実際のクローラーにどのような対処が有効か?ともに探求してくれる方も歓迎します。
この記事が役に立ったら「いいね」!
